Refraction of Light in EnergyPlus

In EnergyPlus, it is possible to find the direction of the beam solar radiation incident on a surface window.
I wondered if EnrgyPlus considers the direction of the Window Transmitted Beam Solar Radiation the same as the incident one?
In reality, the window glass has an index of refraction that causes changes in the transmitted beam solar radiation direction (due to refraction of light) when it comes from a medium with a different index of refraction such as air.
I wanted to know if EnergyPlus considers this direction change when the light passes through media with different indexes of refractions?


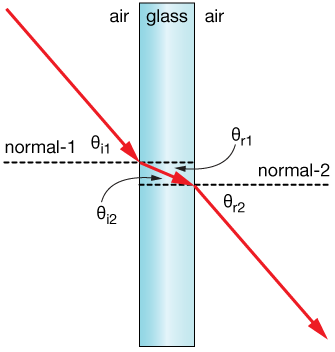




you can check this post link text
Thanks for the link. I checked it out. But I didn't find anything regarding the refraction of light.