
Context:
- I am working with project_singlefamilydetached from the ResStock project
- I have location.tsv and location-region.tsv fixed to only simulate homes in Alpena, Michigan
- I have changed the vintage.tsv for Alpena, Michigan to my own probabilities of my choosing
I have been using PAT tool to simulate differences in energy use for homes with a Propane Furnace only vs. GSHP only. However, I noticed that for different seeds, the building characteristics remain identical after analysis has finished.
An example is shown below:
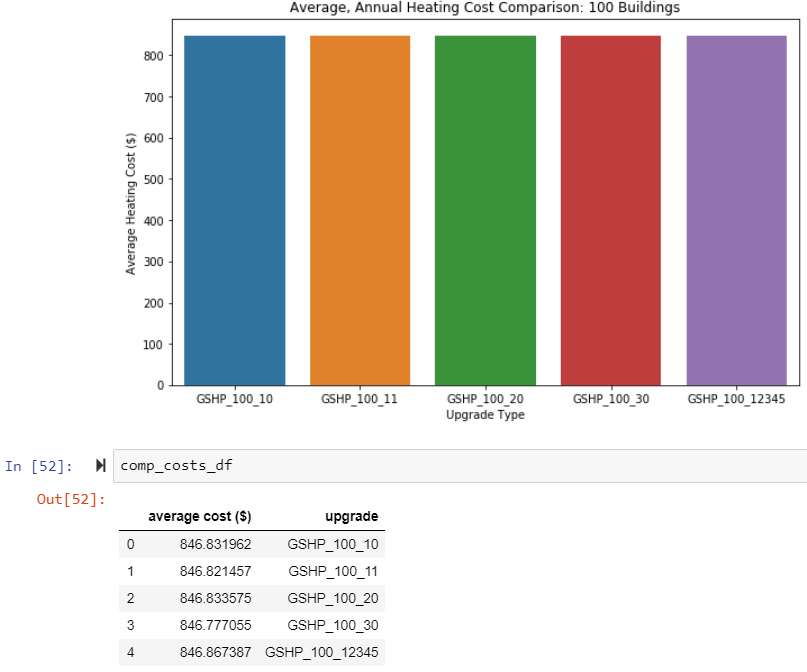
The average, annual total heating costs for 5 different analyses, with 5 unique seeds, produce almost identical values. To produce the results you see before you, I utilized the electricity_heating_kwh and propane_heating_mbtu outputs from the enduse_timeseries.csv for each of the buildings.
If changing the seeds does not change the outputs of enduse_timeseries.csv, then, what does it change? I wish to create a distribution of comparisons, but in order to do that, the results outputted by PAT needs to change as well.


