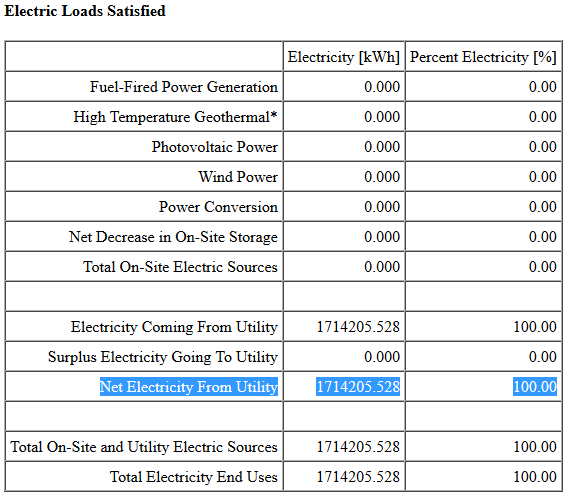
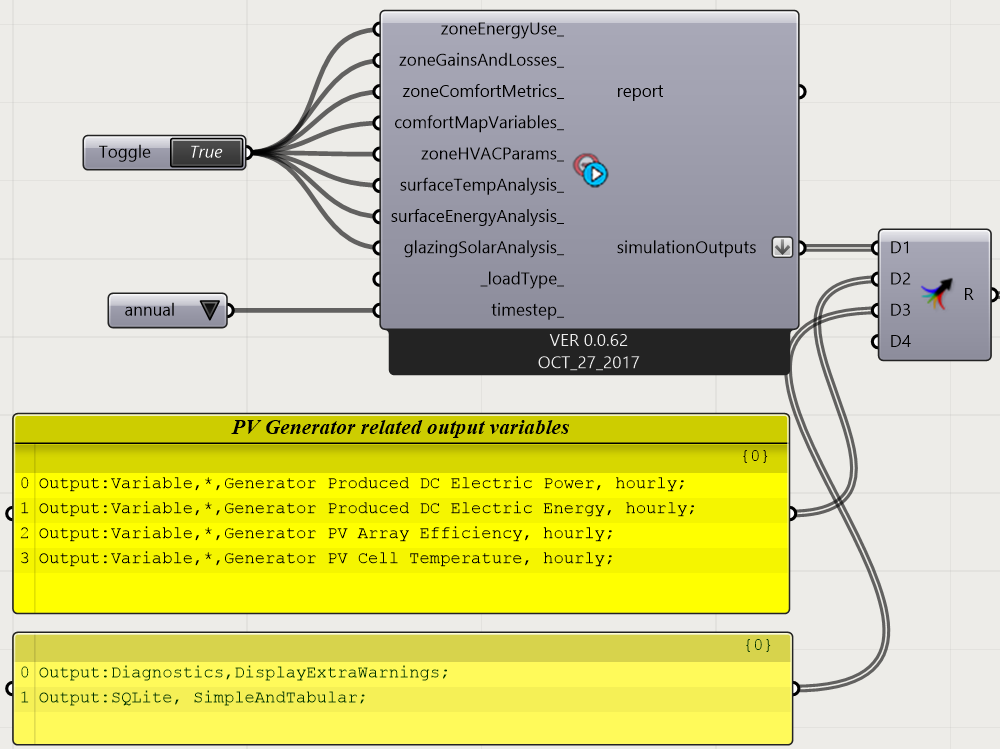
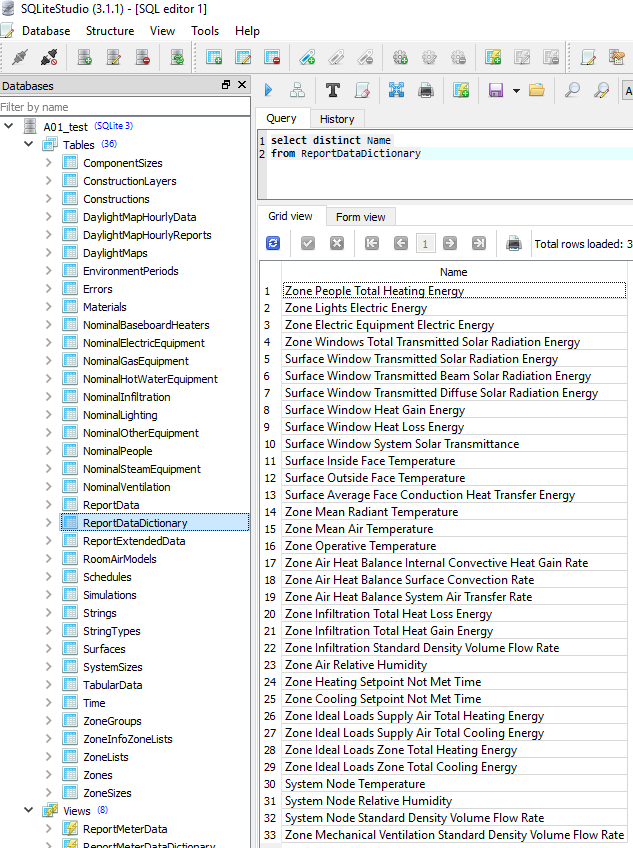
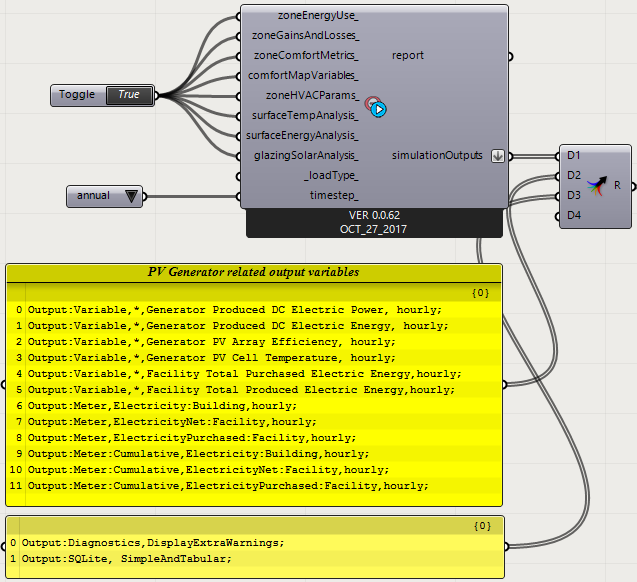
If you're using the Output:SQLite object to write EnergyPlus outputs to an SQLite file, then you should set the Option input field to 'SimpleAndTabular' to include time-series and tabular reports found in the HTML file. After doing that, you should be able to find within the SQL file the Net Electricity From Utility output that you highlighted above.
For adding info to the CSV output file, you have a few options using Output:Variable and Output:Meter objects.
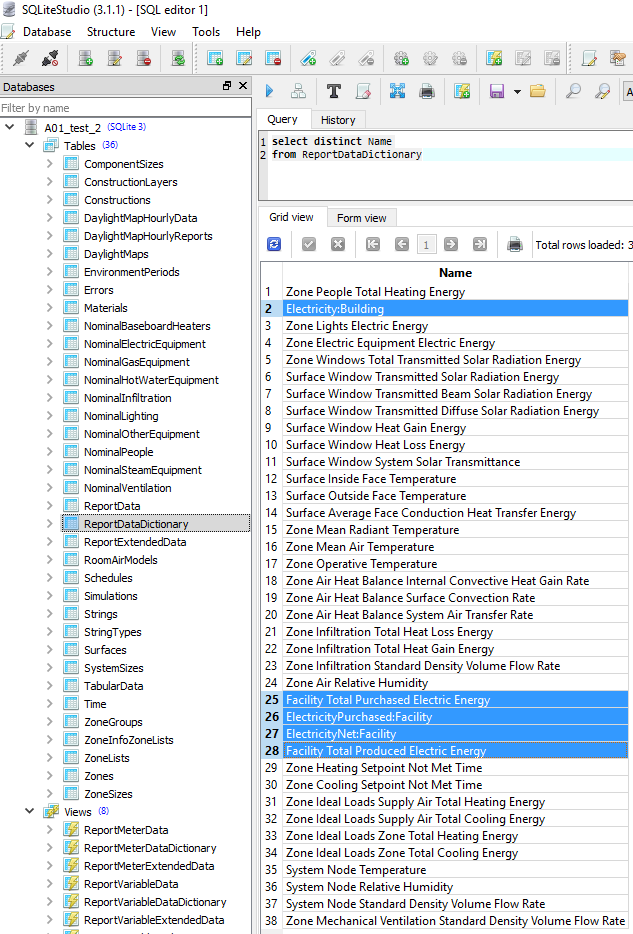
Output:Variable options from the .rdd output file
Output:Variable,*,Facility Total Purchased Electric Energy,hourly; !- HVAC Sum [J]
Output:Variable,*,Facility Total Produced Electric Energy,hourly; !- HVAC Sum [J]
Output:Meter options from the .mdd output file
Output:Meter,Electricity:Building,hourly; !- [J]
Output:Meter,ElectricityNet:Facility,hourly; !- [J]
Output:Meter,ElectricityPurchased:Facility,hourly; !- [J]
Each Output:Meter option also has a reciprocal Output:Meter:Cumulative object in the .mdd output file. If you add a cumulative meter, that will show a running total of electricity use instead of only electricity use for your chosen reporting frequency (timestep, hourly, etc.) in the variables output CSV file that contains Output:Variable results, as well as the meter output CSV file EnergyPlus generates with the same name as your input IDF file.
Output:Meter:Cumulative,Electricity:Building,hourly; !- [J]
Output:Meter:Cumulative,ElectricityNet:Facility,hourly; !- [J]
Output:Meter:Cumulative,ElectricityPurchased:Facility,hourly; !- [J]
Note that "Building" meters sum each zone's energy use while "Facility" meters sum ALL the energy (building + HVAC + exterior) of a given fuel type.