Question-and-Answer Resource for the Building Energy Modeling Community
First time here? Check out the Help page!
| | 1 | initial version |
Using eppy:
In [1]:
import eppy.EPlusInterfaceFunctions.parse_idd as parse_idd
iddfile = "/Applications/EnergyPlus-8-6-0/Energy+.idd"
IDF.setiddname(iddfile)
x = parse_idd.extractidddata(iddfile)
useful = x[2]
The most useful (IMHO) is the second element of the 4-tuple x
That's a list of each idd object, each idd object being a list of dict where the first element (index 0) is the object itself, and the following are each field.
Example:
In [2]: useful[6]
Out[2]:
[{'format': ['singleLine'],
'group': 'Simulation Parameters',
'idfobj': 'SurfaceConvectionAlgorithm:Inside',
'memo': ['Default indoor surface heat transfer convection algorithm to be used for all zones'],
'unique-object': ['']},
{'default': ['TARP'],
'field': ['Algorithm'],
'key': ['Simple', 'TARP', 'CeilingDiffuser', 'AdaptiveConvectionAlgorithm'],
'note': ['Simple = constant value natural convection (ASHRAE)',
'TARP = variable natural convection based on temperature difference (ASHRAE, Walton)',
'CeilingDiffuser = ACH-based forced and mixed convection correlations',
'for ceiling diffuser configuration with simple natural convection limit',
'AdaptiveConvectionAlgorithm = dynamic selection of convection models based on conditions'],
'type': ['choice']}]
Here's a way you would print each object and their fields (there's much more info) for the first few objects of the idd
In [3]:
for k in useful[2:5]:
print(k[0]['idfobj'])
for j in k[1:]:
print("---- {}".format(j['field'][0]))
Out[3]:
Version
---- Version Identifier
SimulationControl
---- Do Zone Sizing Calculation
---- Do System Sizing Calculation
---- Do Plant Sizing Calculation
---- Run Simulation for Sizing Periods
---- Run Simulation for Weather File Run Periods
---- Do HVAC Sizing Simulation for Sizing Periods
---- Maximum Number of HVAC Sizing Simulation Passes
Building
---- Name
---- North Axis
---- Terrain
---- Loads Convergence Tolerance Value
---- Temperature Convergence Tolerance Value
---- Solar Distribution
---- Maximum Number of Warmup Days
---- Minimum Number of Warmup Days
| | 2 | No.2 Revision |
Using
In [1]:
import eppy.EPlusInterfaceFunctions.parse_idd as parse_idd
iddfile = "/Applications/EnergyPlus-8-6-0/Energy+.idd"
IDF.setiddname(iddfile)
x = parse_idd.extractidddata(iddfile)
useful = x[2]
The most useful (IMHO) is the second element of the 4-tuple x
That's a list of each idd object, each idd object being a list of dict where the first element (index 0) is the object itself, and the following are each field.
Example:
In [2]: useful[6]
Out[2]:
[{'format': ['singleLine'],
'group': 'Simulation Parameters',
'idfobj': 'SurfaceConvectionAlgorithm:Inside',
'memo': ['Default indoor surface heat transfer convection algorithm to be used for all zones'],
'unique-object': ['']},
{'default': ['TARP'],
'field': ['Algorithm'],
'key': ['Simple', 'TARP', 'CeilingDiffuser', 'AdaptiveConvectionAlgorithm'],
'note': ['Simple = constant value natural convection (ASHRAE)',
'TARP = variable natural convection based on temperature difference (ASHRAE, Walton)',
'CeilingDiffuser = ACH-based forced and mixed convection correlations',
'for ceiling diffuser configuration with simple natural convection limit',
'AdaptiveConvectionAlgorithm = dynamic selection of convection models based on conditions'],
'type': ['choice']}]
Here's a way you would print each object and their fields (there's much more info) for the first few objects of the idd
In [3]:
for k in useful[2:5]:
print(k[0]['idfobj'])
for j in k[1:]:
print("---- {}".format(j['field'][0]))
Out[3]:
Version
---- Version Identifier
SimulationControl
---- Do Zone Sizing Calculation
---- Do System Sizing Calculation
---- Do Plant Sizing Calculation
---- Run Simulation for Sizing Periods
---- Run Simulation for Weather File Run Periods
---- Do HVAC Sizing Simulation for Sizing Periods
---- Maximum Number of HVAC Sizing Simulation Passes
Building
---- Name
---- North Axis
---- Terrain
---- Loads Convergence Tolerance Value
---- Temperature Convergence Tolerance Value
---- Solar Distribution
---- Maximum Number of Warmup Days
---- Minimum Number of Warmup Days
This will print each object and its field, as well as save it into a hash (key = idd object name, value = list of fields)
h = {}
factory = OpenStudio::IddFileAndFactoryWrapper.new("EnergyPlus".to_IddFileType)
factory.objects.each do |obj|
n = obj.numFields
l = []
puts obj.name.to_s
obj.nonextensibleFields.each do |field|
puts "---- #{field.name.to_s}"
l << field.name.to_s
end
if l.length < n
puts "ERROR, missing fields"
end
h[obj.name.to_s] = l
end
| | 3 | No.3 Revision |
In [1]:
import eppy.EPlusInterfaceFunctions.parse_idd as parse_idd
iddfile = "/Applications/EnergyPlus-8-6-0/Energy+.idd"
IDF.setiddname(iddfile)
x = parse_idd.extractidddata(iddfile)
useful = x[2]
The most useful (IMHO) is the second element of the 4-tuple x
That's a list of each idd object, each idd object being a list of dict where the first element (index 0) is the object itself, and the following are each field.
Example:
In [2]: useful[6]
Out[2]:
[{'format': ['singleLine'],
'group': 'Simulation Parameters',
'idfobj': 'SurfaceConvectionAlgorithm:Inside',
'memo': ['Default indoor surface heat transfer convection algorithm to be used for all zones'],
'unique-object': ['']},
{'default': ['TARP'],
'field': ['Algorithm'],
'key': ['Simple', 'TARP', 'CeilingDiffuser', 'AdaptiveConvectionAlgorithm'],
'note': ['Simple = constant value natural convection (ASHRAE)',
'TARP = variable natural convection based on temperature difference (ASHRAE, Walton)',
'CeilingDiffuser = ACH-based forced and mixed convection correlations',
'for ceiling diffuser configuration with simple natural convection limit',
'AdaptiveConvectionAlgorithm = dynamic selection of convection models based on conditions'],
'type': ['choice']}]
Here's a way you would print each object and their fields (there's much more info) for the first few objects of the idd
In [3]:
for k in useful[2:5]:
print(k[0]['idfobj'])
for j in k[1:]:
print("---- {}".format(j['field'][0]))
Out[3]:
Version
---- Version Identifier
SimulationControl
---- Do Zone Sizing Calculation
---- Do System Sizing Calculation
---- Do Plant Sizing Calculation
---- Run Simulation for Sizing Periods
---- Run Simulation for Weather File Run Periods
---- Do HVAC Sizing Simulation for Sizing Periods
---- Maximum Number of HVAC Sizing Simulation Passes
Building
---- Name
---- North Axis
---- Terrain
---- Loads Convergence Tolerance Value
---- Temperature Convergence Tolerance Value
---- Solar Distribution
---- Maximum Number of Warmup Days
---- Minimum Number of Warmup Days
This will print each object and its field, as well as save it into a hash (key = idd object name, value = list of fields)
h = {}
factory = OpenStudio::IddFileAndFactoryWrapper.new("EnergyPlus".to_IddFileType)
factory.objects.each do |obj|
n = obj.numFields
l = []
puts obj.name.to_s
obj.nonextensibleFields.each do |field|
puts "---- #{field.name.to_s}"
l << field.name.to_s
end
if l.length < n
puts "ERROR, missing fields"
end
h[obj.name.to_s] = l
end
Of course you can access more info out of each field, for example field.properties.required, field.properties.note, field.properties.units.get, etc, etc
| | 4 | No.4 Revision |
In [1]:
import eppy.EPlusInterfaceFunctions.parse_idd as parse_idd
iddfile = "/Applications/EnergyPlus-8-6-0/Energy+.idd"
IDF.setiddname(iddfile)
x = parse_idd.extractidddata(iddfile)
useful = x[2]
The most useful (IMHO) is the second element of the 4-tuple x
That's a list of each idd object, each idd object being a list of dict where the first element (index 0) is the object itself, and the following are each field.
Example:
In [2]: useful[6]
Out[2]:
[{'format': ['singleLine'],
'group': 'Simulation Parameters',
'idfobj': 'SurfaceConvectionAlgorithm:Inside',
'memo': ['Default indoor surface heat transfer convection algorithm to be used for all zones'],
'unique-object': ['']},
{'default': ['TARP'],
'field': ['Algorithm'],
'key': ['Simple', 'TARP', 'CeilingDiffuser', 'AdaptiveConvectionAlgorithm'],
'note': ['Simple = constant value natural convection (ASHRAE)',
'TARP = variable natural convection based on temperature difference (ASHRAE, Walton)',
'CeilingDiffuser = ACH-based forced and mixed convection correlations',
'for ceiling diffuser configuration with simple natural convection limit',
'AdaptiveConvectionAlgorithm = dynamic selection of convection models based on conditions'],
'type': ['choice']}]
Here's a way you would print each object and their fields (there's much more info) for the first few objects of the idd
In [3]:
for k in useful[2:5]:
print(k[0]['idfobj'])
for j in k[1:]:
print("---- {}".format(j['field'][0]))
Out[3]:
Version
---- Version Identifier
SimulationControl
---- Do Zone Sizing Calculation
---- Do System Sizing Calculation
---- Do Plant Sizing Calculation
---- Run Simulation for Sizing Periods
---- Run Simulation for Weather File Run Periods
---- Do HVAC Sizing Simulation for Sizing Periods
---- Maximum Number of HVAC Sizing Simulation Passes
Building
---- Name
---- North Axis
---- Terrain
---- Loads Convergence Tolerance Value
---- Temperature Convergence Tolerance Value
---- Solar Distribution
---- Maximum Number of Warmup Days
---- Minimum Number of Warmup Days
This will print each object and its field, as well as save it into a hash (key = idd object name, value = list of fields)
h = {}
factory = OpenStudio::IddFileAndFactoryWrapper.new("EnergyPlus".to_IddFileType)
factory.objects.each do |obj|
n = obj.numFields
l = []
puts obj.name.to_s
obj.nonextensibleFields.each do |field|
puts "---- #{field.name.to_s}"
l << field.name.to_s
end
if l.length < n
puts "ERROR, missing fields"
end
h[obj.name.to_s] = l
end
Of course you can access more info out of each field, for example field.properties.required, field.properties.note, field.properties.units.get, etc, etc
| | 5 | No.5 Revision |
In [1]:
import eppy.EPlusInterfaceFunctions.parse_idd as parse_idd
iddfile = "/Applications/EnergyPlus-8-6-0/Energy+.idd"
IDF.setiddname(iddfile)
x = parse_idd.extractidddata(iddfile)
useful = x[2]
The most useful (IMHO) is the second element of the 4-tuple x
That's a list of each idd object, each idd object being a list of dict where the first element (index 0) is the object itself, and the following are each field.
Example:
In [2]: useful[6]
Out[2]:
[{'format': ['singleLine'],
'group': 'Simulation Parameters',
'idfobj': 'SurfaceConvectionAlgorithm:Inside',
'memo': ['Default indoor surface heat transfer convection algorithm to be used for all zones'],
'unique-object': ['']},
{'default': ['TARP'],
'field': ['Algorithm'],
'key': ['Simple', 'TARP', 'CeilingDiffuser', 'AdaptiveConvectionAlgorithm'],
'note': ['Simple = constant value natural convection (ASHRAE)',
'TARP = variable natural convection based on temperature difference (ASHRAE, Walton)',
'CeilingDiffuser = ACH-based forced and mixed convection correlations',
'for ceiling diffuser configuration with simple natural convection limit',
'AdaptiveConvectionAlgorithm = dynamic selection of convection models based on conditions'],
'type': ['choice']}]
Here's a way you would print each object and their fields (there's much more info) for the first few objects of the idd
In [3]:
for k in useful[2:5]:
print(k[0]['idfobj'])
for j in k[1:]:
print("---- {}".format(j['field'][0]))
Out[3]:
Version
---- Version Identifier
SimulationControl
---- Do Zone Sizing Calculation
---- Do System Sizing Calculation
---- Do Plant Sizing Calculation
---- Run Simulation for Sizing Periods
---- Run Simulation for Weather File Run Periods
---- Do HVAC Sizing Simulation for Sizing Periods
---- Maximum Number of HVAC Sizing Simulation Passes
Building
---- Name
---- North Axis
---- Terrain
---- Loads Convergence Tolerance Value
---- Temperature Convergence Tolerance Value
---- Solar Distribution
---- Maximum Number of Warmup Days
---- Minimum Number of Warmup Days
This will print each object and its field, as well as save it into a hash (key = idd object name, value = list of fields)
h = {}
factory = OpenStudio::IddFileAndFactoryWrapper.new("EnergyPlus".to_IddFileType)
factory.objects.each do |obj|
n = obj.numFields
l = []
puts obj.name.to_s
obj.nonextensibleFields.each do |field|
puts "---- #{field.name.to_s}"
l << field.name.to_s
end
if l.length < n
puts "ERROR, missing fields"
end
h[obj.name.to_s] = l
end
Of course you can access more info out of each field, for example field.properties.required, field.properties.note, field.properties.units.get, etc, etc
E+ 8.7 release is in preparation and will include a new "JDD" for JSON input Data Dictionary, the JSON equivalent of the IDD. Currently this is on a separate development branch, but here's the input_processor_refactor/idd/Energy+.jdd.in.
I'm gonna propose a Python and a Ruby version to parse this file, print the fields for each object as well as store a simple dict/hash where the key is the object type, and the value is a list of the fields for each object. Of course, there's way more information in the JDD, use it as you want.
import json
import urllib.request
jdd_url = 'https://raw.githubusercontent.com/NREL/EnergyPlus/input_processor_refactor/idd/Energy%2B.jdd.in'
jdd_txt = urllib.request.urlopen(jdd_url).read().decode('utf8')
jdd = json.loads(jdd_txt)
jdd_objects = jdd['properties']
# Dict to store results: key is the object type, value is a list of fields
simple_dict = {}
for idd_obj_name, idd_obj in jdd_objects.items():
print(idd_obj_name)
list_fields = jdd_objects['Wall:Interzone']['legacy_idd']['fields']
simple_dict[idd_obj_name] = list_fields
print('\n'.join('---- {}'.format(item) for item in list_fields))
require 'json'
require 'open-uri'
jdd_url = 'https://raw.githubusercontent.com/NREL/EnergyPlus/input_processor_refactor/idd/Energy%2B.jdd.in'
data_hash = JSON.parse open(jdd_url).read
simple_h = {}
data_hash['properties'].each do |idd_obj_name, idd_obj|
list_fields = idd_obj['legacy_idd']['fields']
simple_h[idd_obj_name] = list_fields
puts idd_obj_name
l.each {|e| puts "---- #{e}"}
end
| | 6 | No.6 Revision |
In [1]:
import eppy.EPlusInterfaceFunctions.parse_idd as parse_idd
iddfile = "/Applications/EnergyPlus-8-6-0/Energy+.idd"
IDF.setiddname(iddfile)
x = parse_idd.extractidddata(iddfile)
useful = x[2]
The most useful (IMHO) is the second element of the 4-tuple x
That's a list of each idd object, each idd object being a list of dict where the first element (index 0) is the object itself, and the following are each field.
Example:
In [2]: useful[6]
Out[2]:
[{'format': ['singleLine'],
'group': 'Simulation Parameters',
'idfobj': 'SurfaceConvectionAlgorithm:Inside',
'memo': ['Default indoor surface heat transfer convection algorithm to be used for all zones'],
'unique-object': ['']},
{'default': ['TARP'],
'field': ['Algorithm'],
'key': ['Simple', 'TARP', 'CeilingDiffuser', 'AdaptiveConvectionAlgorithm'],
'note': ['Simple = constant value natural convection (ASHRAE)',
'TARP = variable natural convection based on temperature difference (ASHRAE, Walton)',
'CeilingDiffuser = ACH-based forced and mixed convection correlations',
'for ceiling diffuser configuration with simple natural convection limit',
'AdaptiveConvectionAlgorithm = dynamic selection of convection models based on conditions'],
'type': ['choice']}]
Here's a way you would print each object and their fields (there's much more info) for the first few objects of the idd
In [3]:
for k in useful[2:5]:
print(k[0]['idfobj'])
for j in k[1:]:
print("---- {}".format(j['field'][0]))
Out[3]:
Version
---- Version Identifier
SimulationControl
---- Do Zone Sizing Calculation
---- Do System Sizing Calculation
---- Do Plant Sizing Calculation
---- Run Simulation for Sizing Periods
---- Run Simulation for Weather File Run Periods
---- Do HVAC Sizing Simulation for Sizing Periods
---- Maximum Number of HVAC Sizing Simulation Passes
Building
---- Name
---- North Axis
---- Terrain
---- Loads Convergence Tolerance Value
---- Temperature Convergence Tolerance Value
---- Solar Distribution
---- Maximum Number of Warmup Days
---- Minimum Number of Warmup Days
This will print each object and its field, as well as save it into a hash (key = idd object name, value = list of fields)
h = {}
factory = OpenStudio::IddFileAndFactoryWrapper.new("EnergyPlus".to_IddFileType)
factory.objects.each do |obj|
n = obj.numFields
l = []
puts obj.name.to_s
obj.nonextensibleFields.each do |field|
puts "---- #{field.name.to_s}"
l << field.name.to_s
end
if l.length < n
puts "ERROR, missing fields"
end
h[obj.name.to_s] = l
end
Of course you can access more info out of each field, for example field.properties.required, field.properties.note, field.properties.units.get, etc, etc
E+ 8.7 release is in preparation and will include a new "JDD" for JSON input Data Dictionary, the JSON equivalent of the IDD. Currently this is on a separate development branch, but here's the input_processor_refactor/idd/Energy+.jdd.in.
I'm gonna propose a Python and a Ruby version to parse this file, print the fields for each object as well as store a simple dict/hash where the key is the object type, and the value is a list of the fields for each object. Of course, there's way more information in the JDD, use it as you want.
import json
import urllib.request
jdd_url = 'https://raw.githubusercontent.com/NREL/EnergyPlus/input_processor_refactor/idd/Energy%2B.jdd.in'
jdd_txt = urllib.request.urlopen(jdd_url).read().decode('utf8')
jdd = json.loads(jdd_txt)
jdd_objects = jdd['properties']
# Dict to store results: key is the object type, value is a list of fields
simple_dict = {}
for idd_obj_name, idd_obj in jdd_objects.items():
print(idd_obj_name)
list_fields = jdd_objects['Wall:Interzone']['legacy_idd']['fields']
simple_dict[idd_obj_name] = list_fields
print('\n'.join('---- {}'.format(item) for item in list_fields))
require 'json'
require 'open-uri'
jdd_url = 'https://raw.githubusercontent.com/NREL/EnergyPlus/input_processor_refactor/idd/Energy%2B.jdd.in'
data_hash = JSON.parse open(jdd_url).read
simple_h = {}
data_hash['properties'].each do |idd_obj_name, idd_obj|
list_fields = idd_obj['legacy_idd']['fields']
simple_h[idd_obj_name] = list_fields
puts idd_obj_name
l.each {|e| puts "---- #{e}"}
end
In IDF Editor, open an new file that contains no objects, and in the HELP menu chose "Create objectList.txt":
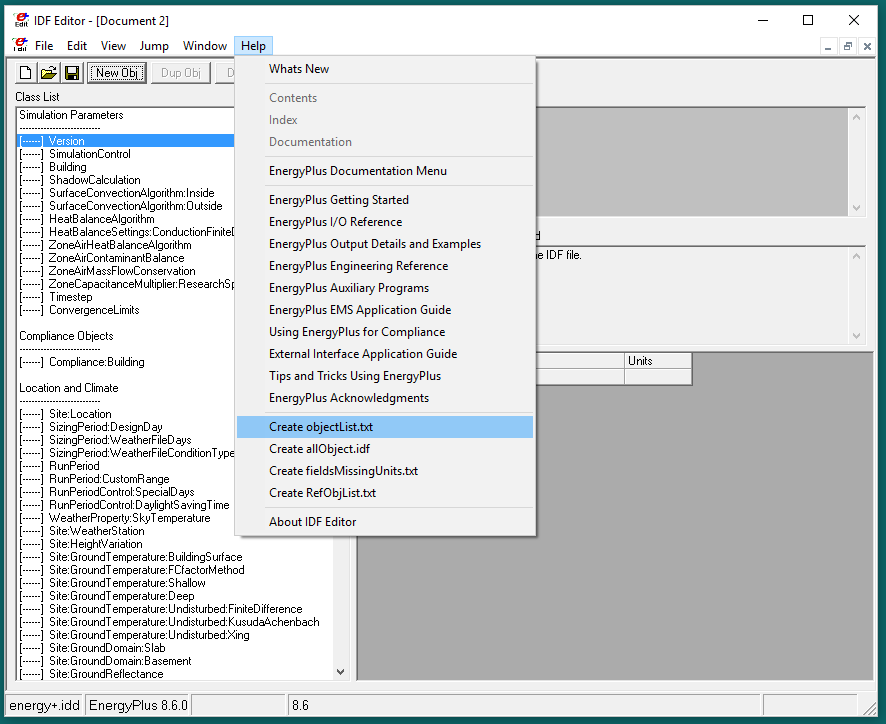
This creates a file that lists all the objects by group. The file ends up in the same directory as the IDF Editor program (c:\EnergyPlusV8-6-0\Preprocess\IDFEditor).
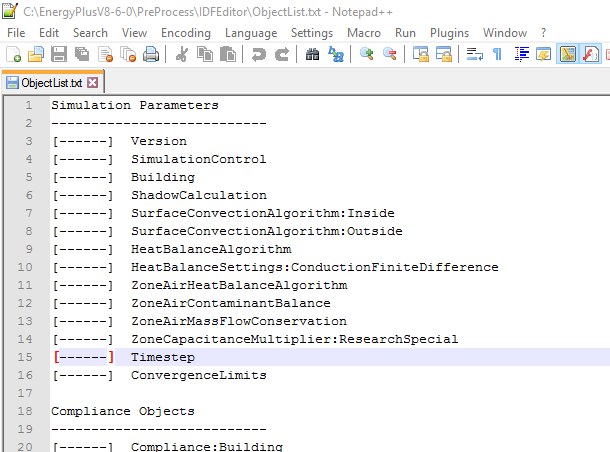
By the way, if you do the same procedure with a file with objects, the number of objects shows up where the dashes are shown.
| | 7 | No.7 Revision |
In [1]:
import eppy.EPlusInterfaceFunctions.parse_idd as parse_idd
iddfile = "/Applications/EnergyPlus-8-6-0/Energy+.idd"
IDF.setiddname(iddfile)
x = parse_idd.extractidddata(iddfile)
useful = x[2]
The most useful (IMHO) is the second element of the 4-tuple x
That's a list of each idd object, each idd object being a list of dict where the first element (index 0) is the object itself, and the following are each field.
Example:
In [2]: useful[6]
Out[2]:
[{'format': ['singleLine'],
'group': 'Simulation Parameters',
'idfobj': 'SurfaceConvectionAlgorithm:Inside',
'memo': ['Default indoor surface heat transfer convection algorithm to be used for all zones'],
'unique-object': ['']},
{'default': ['TARP'],
'field': ['Algorithm'],
'key': ['Simple', 'TARP', 'CeilingDiffuser', 'AdaptiveConvectionAlgorithm'],
'note': ['Simple = constant value natural convection (ASHRAE)',
'TARP = variable natural convection based on temperature difference (ASHRAE, Walton)',
'CeilingDiffuser = ACH-based forced and mixed convection correlations',
'for ceiling diffuser configuration with simple natural convection limit',
'AdaptiveConvectionAlgorithm = dynamic selection of convection models based on conditions'],
'type': ['choice']}]
Here's a way you would print each object and their fields (there's much more info) for the first few objects of the idd
In [3]:
for k in useful[2:5]:
print(k[0]['idfobj'])
for j in k[1:]:
print("---- {}".format(j['field'][0]))
Out[3]:
Version
---- Version Identifier
SimulationControl
---- Do Zone Sizing Calculation
---- Do System Sizing Calculation
---- Do Plant Sizing Calculation
---- Run Simulation for Sizing Periods
---- Run Simulation for Weather File Run Periods
---- Do HVAC Sizing Simulation for Sizing Periods
---- Maximum Number of HVAC Sizing Simulation Passes
Building
---- Name
---- North Axis
---- Terrain
---- Loads Convergence Tolerance Value
---- Temperature Convergence Tolerance Value
---- Solar Distribution
---- Maximum Number of Warmup Days
---- Minimum Number of Warmup Days
This will print each object and its field, as well as save it into a hash (key = idd object name, value = list of fields)
h = {}
factory = OpenStudio::IddFileAndFactoryWrapper.new("EnergyPlus".to_IddFileType)
factory.objects.each do |obj|
n = obj.numFields
l = []
puts obj.name.to_s
obj.nonextensibleFields.each do |field|
puts "---- #{field.name.to_s}"
l << field.name.to_s
end
if l.length < n
puts "ERROR, missing fields"
end
h[obj.name.to_s] = l
end
Of course you can access more info out of each field, for example field.properties.required, field.properties.note, field.properties.units.get, etc, etc
E+ 8.7 release is in preparation and will include a new "JDD" for JSON input Data Dictionary, the JSON equivalent of the IDD. Currently this is on a separate development branch, but here's the input_processor_refactor/idd/Energy+.jdd.in.
I'm gonna propose a Python and a Ruby version to parse this file, print the fields for each object as well as store a simple dict/hash where the key is the object type, and the value is a list of the fields for each object. Of course, there's way more information in the JDD, use it as you want.
import json
import urllib.request
jdd_url = 'https://raw.githubusercontent.com/NREL/EnergyPlus/input_processor_refactor/idd/Energy%2B.jdd.in'
jdd_txt = urllib.request.urlopen(jdd_url).read().decode('utf8')
jdd = json.loads(jdd_txt)
jdd_objects = jdd['properties']
# Dict to store results: key is the object type, value is a list of fields
simple_dict = {}
for idd_obj_name, idd_obj in jdd_objects.items():
print(idd_obj_name)
list_fields = jdd_objects['Wall:Interzone']['legacy_idd']['fields']
simple_dict[idd_obj_name] = list_fields
print('\n'.join('---- {}'.format(item) for item in list_fields))
require 'json'
require 'open-uri'
jdd_url = 'https://raw.githubusercontent.com/NREL/EnergyPlus/input_processor_refactor/idd/Energy%2B.jdd.in'
data_hash = JSON.parse open(jdd_url).read
simple_h = {}
data_hash['properties'].each do |idd_obj_name, idd_obj|
list_fields = idd_obj['legacy_idd']['fields']
simple_h[idd_obj_name] = list_fields
puts idd_obj_name
l.each {|e| puts "---- #{e}"}
end
In IDF Editor, open an new file that contains no objects, and in the HELP menu chose "Create objectList.txt":
This creates a file that lists all the objects by group. The file ends up in the same directory as the IDF Editor program (c:\EnergyPlusV8-6-0\Preprocess\IDFEditor).
By the way, if you do the same procedure with a file with objects, the number of objects shows up where the dashes are shown.




