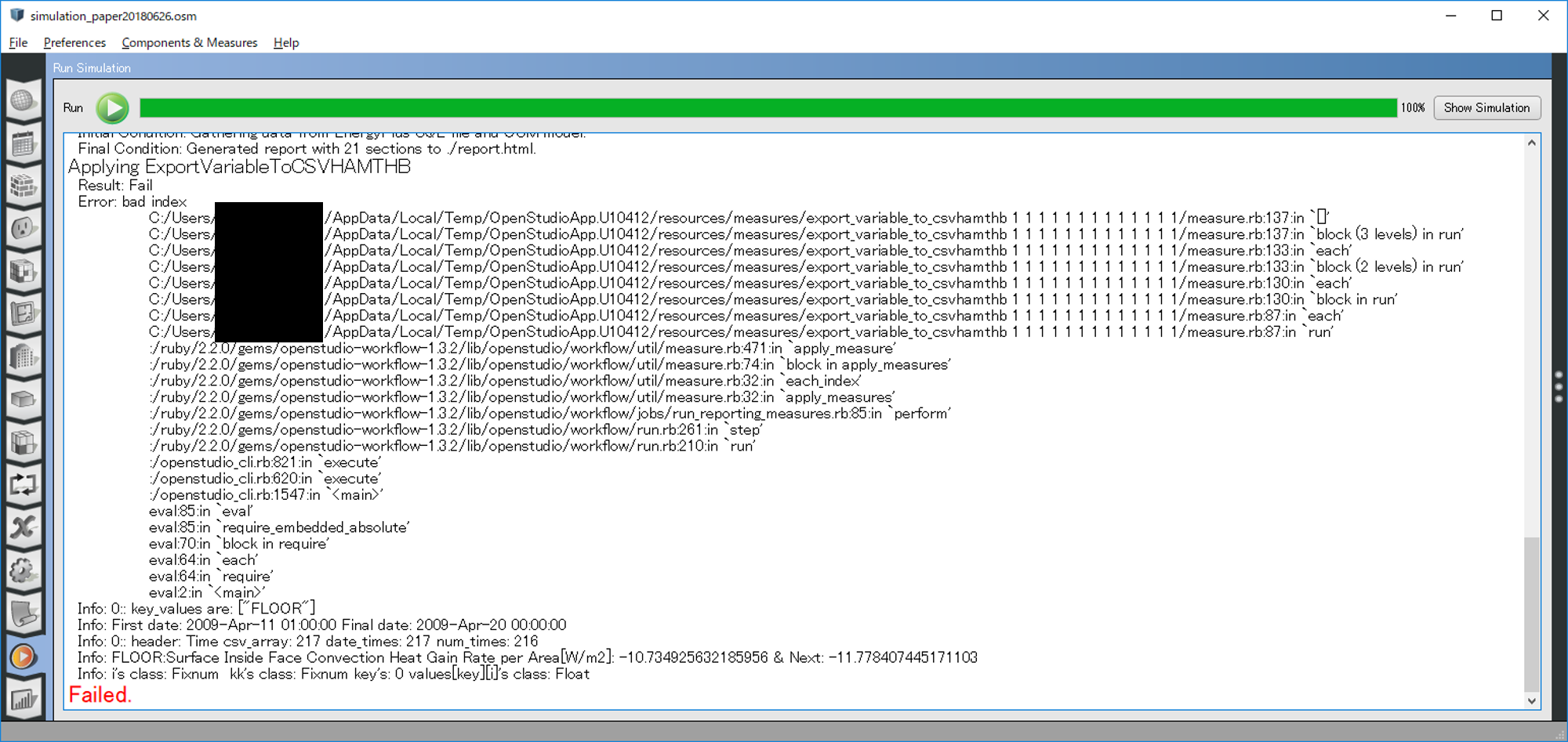
Dear the members of unmet-hours,
Currently, I'm writing measure to output the surface inside conduction in HAMT simulation by outputting variables surface heat balances in a table. (Related to this question)
I already modified "Add Output Variables" and succeeded. After that, currently I am trying to output those variables in one table by modifying "Export Variable To CSV".
When applying the code, the error message "bad index" comes up again and again... But in the error check sentence I added, index worked. I would like to know what the cause of this is.
Please check the code below (I am modifying "Export Varible To CSV"'s L.91 and below mainly).
variable_names = sqlFile.availableVariableNames(ann_env_pd, reporting_frequency)
heles = ["Surface Inside Face Convection Heat Gain Rate per Area","Surface Inside Face Net Surface Thermal Radiation Heat Gain Rate per Area","Surface Inside Face Solar Radiation Heat Gain Rate per Area","Surface Inside Face Lights Radiation Heat Gain Rate","Surface Inside Face Internal Gains Radiation Heat Gain Rate per Area","Surface Inside Face System Radiation Heat Gain Rate per Area"]
csv_array = []
cnt=0
for e in 0..5
hele=heles[e]
if !variable_names.include? "#{hele}"
runner.registerError("#{hele} is not in sqlFile. Please add an AddOutputVariable reporting measure with this variable and run again.")
else
#headers = ["#{reporting_frequency}"]
headers = []
output_timeseries = {}
key_values = sqlFile.availableKeyValues(ann_env_pd, reporting_frequency, hele.to_s)
if key_values.size == 0
runner.registerError("Timeseries for #{hele} did not have any key values. No timeseries available.")
end
key_values.each do |key_value|
timeseries = sqlFile.timeSeries(ann_env_pd, reporting_frequency, hele.to_s, key_value.to_s)
if !timeseries.empty?
timeseries = timeseries.get
units = timeseries.units
headers << "#{key_value.to_s}:#{hele.to_s}[#{units}]"
output_timeseries[headers[-1]] = timeseries
else
runner.registerWarning("Timeseries for #{key_value} #{hele} is empty.")
end
end
earray = []
earray << headers
date_times = ["Time"] + output_timeseries[output_timeseries.keys[0]].dateTimes
values = {}
for key in output_timeseries.keys
kk=headers.find_index(key)
values[kk] = output_timeseries[key].values
end
num_times = date_times.size - 1
if e==0
csv_array << date_times
end
for i in 0..num_times
row = []
for key in headers
kk=headers.find_index(key)
runner.registerInfo("#{key}: #{values[kk][i]} & Next: #{values[kk][i+1]}") if i==0
value = values[kk][i]
row << value
end
earray << row
end
csv_array << earray
end
end
for i in 0..6
end
csv_array=csv_array.transpose
File.open("./report_condHFinHAMT_#{reporting_frequency.delete(' ')}.csv", 'wb') do |file|
csv_array.each do |elem|
file.puts elem.join(',')
end
end
runner.registerInfo("Output file written to #{File.expand_path('.')}")
# close the sql file
sqlFile.close()
*Actually, usually I use the fortran for main. I have a poor knowledge about Ruby coding...