PAT NSGA2 Algorithm problem




Hi everyone,
I have been trying to use PAT to calibrate a building model using NSGA2 as optimization algorithm. Since this analysis might take quite a lot of simulations (10.000+), parallelization is important to reduce total experiment time.
The problem i am having is that when i set the "Max Queued Jobs" algorithm setting higher than 60 some of the simulation datapoints appear as "NA" and also some as "datapoint failure" (This does not happen when that setting is bellow 60).
Since the "Number of Samples" (size of initial population) i am using is around 136, the "Max Queued Jobs" setting is limiting the max simulations i can run at the same time.
Here is an example of what happens:
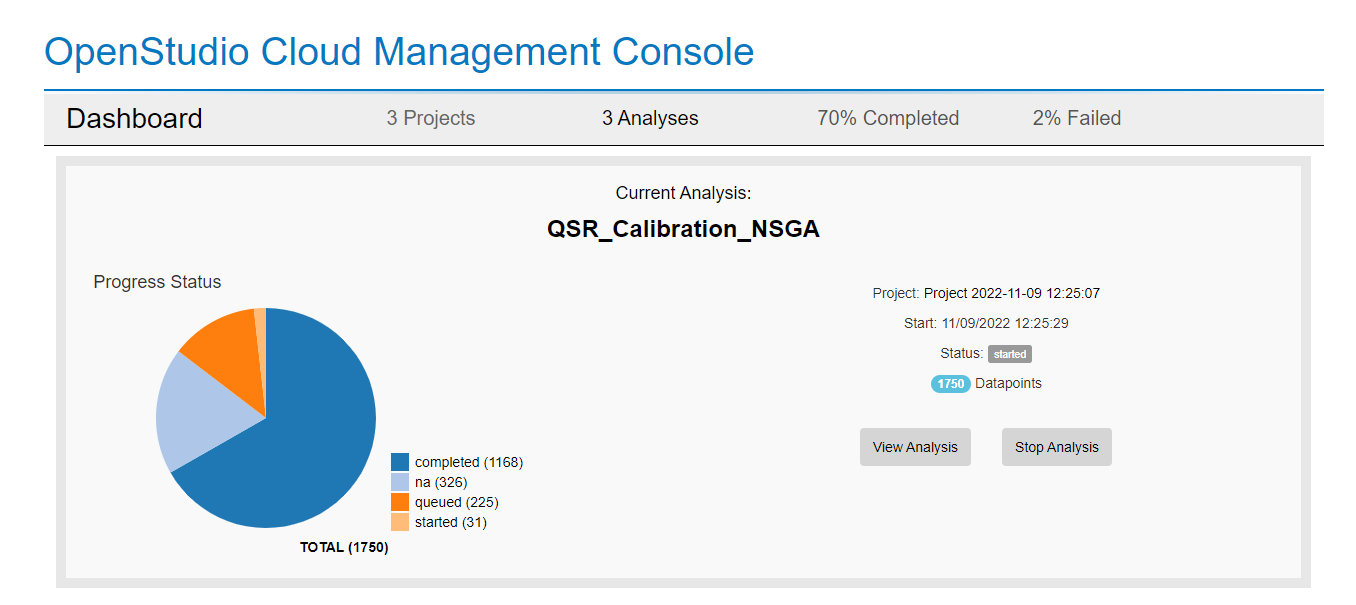
I am using OpenStudio-Server on AWS, with a node type "t3.xlarge".
I will post some screenshots of console errors when i have the chance.
Thanks!
Just an update:
After some testing i have managed to increase the number of "Max Queued Jobs" and consequently the number of parallel simulations by changing some of the OpenStudio-server chart settings. This are the settings i have used:
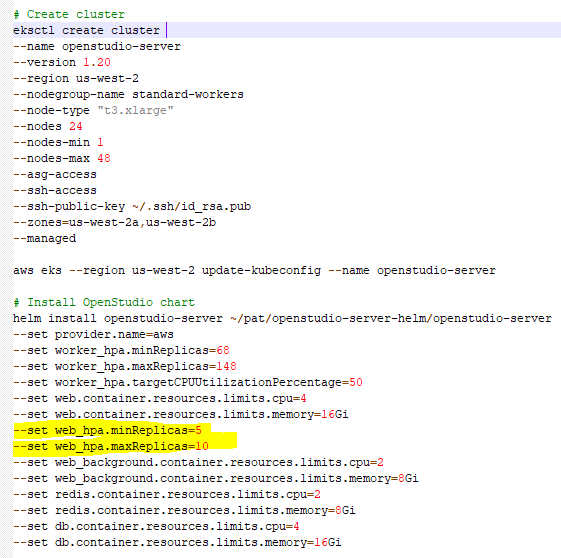
I have increased the resource limits of CPU and memory for all the workers unrelated to the simulation (web_background, etc.) but also the min and max replicas for the web pod (in yellow).
Can someone tell if this is Ok, or i am doing something wrong?
Thanks again!




