I performed my testing on an i7-6700K. I used OpenStudio PAT on a pretty simple model with eight design alternatives that each had one (the same) measure associated with them. To control how many EP engines were called at a time I adjusted the Max Local Processes value found under Preferences->Show Tools. I changed this value from one to seven letting all eight design alternatives complete each time. I didn’t run the baseline since that was missing the measure that was applied to the design alternatives.
The following chart shows what I’m calling the ‘Effective Iteration Runtime’. This value is the total parametric analysis runtime divided by the iterations performed (eight in every case). For example, for the case that was only allowed two processes, the effective iteration runtime was twenty-four seconds, and multiplying this times eight shows that the entire analysis took three minutes and twelve seconds.
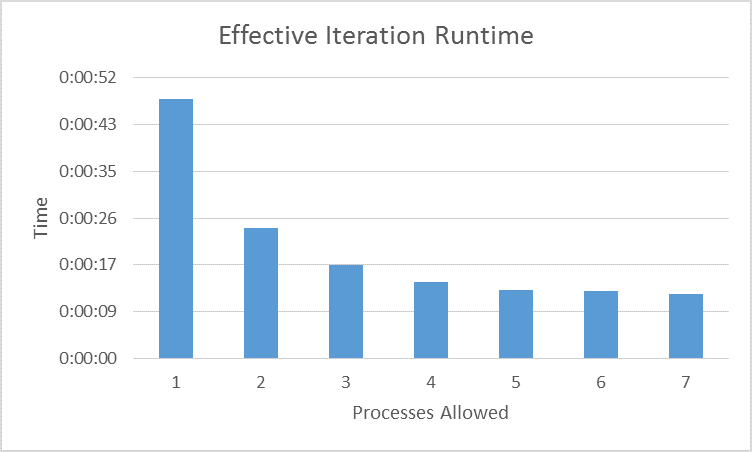
We see an exponential taper from one to four processes allowed with five, six, and seven taking most nearly the same amount of time. I believe this to be an artifact of hyper-threading since this is a four core hyper-threaded machine. What this means is that the ‘block’ of seven runs took 175% longer to run than the ‘block’ on one run. Slightly counter-intuitive to me since I have an eight thread machine, I should be able to run seven identical processes in the same amount of time it takes me to run one of those processes. I guess I hadn’t really put much thought into how hyper-threading scales. I’m guessing it might have something to do with cache/resource sharing, but I ain’t no processor designer!
I wanted to ensure that the hyper-threading wasn’t affecting the results of one to three process allowed results so I disabled it and ran those three tests again. The results were reasonably consistent.
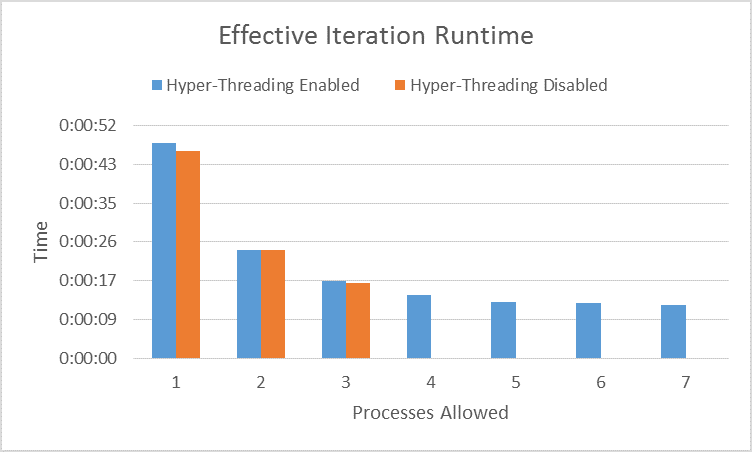
So what does all this mean? It means that at five, six, and seven processes (since those extra processes will in theory be assigned to the ‘hyper-threads’) you’re getting inconsequentially small reductions in entire analysis runtimes (remember, this is specific to my hardware setup). While you’re able to run MORE models at once, the blocks run SLOWER. It’s not even a statistically significant difference with respect to the decrease in analysis runtime.
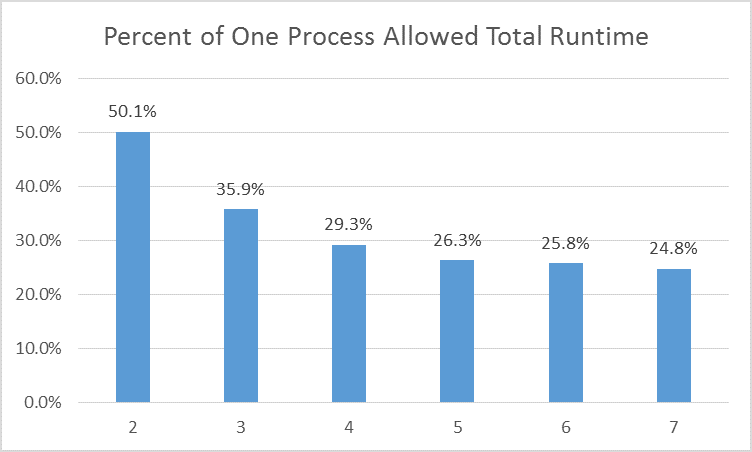
I quickly threw this together more for my own edification, so free feel to call BS on something. Interested to see other people’s thought and if they’ve experienced something similar. Happy to add more detail if someone’s curious about a particular aspect of my approach.
Hopefully you found this interesting :)


